隨著大數據時代的到來,企業(yè)和組織面臨著海量數據處理和存儲的嚴峻挑戰(zhàn)。傳統(tǒng)的集中式數據處理模式在處理大規(guī)模數據時往往遇到性能瓶頸、存儲壓力以及擴展性不足等問題。數據分片處理技術應運而生,作為一種創(chuàng)新的數據處理與存儲支持服務,它通過將數據分散到多個節(jié)點進行并行處理,顯著提升了系統(tǒng)的性能和可靠性。本文將深入探討數據分片處理技術的核心原理、應用場景以及其在現(xiàn)代數據處理與存儲支持服務中的重要作用。
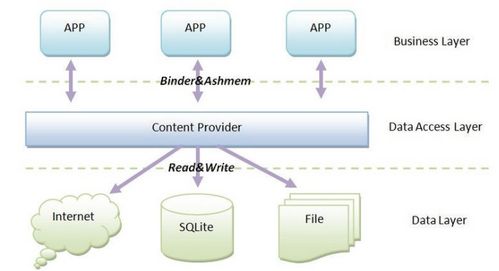
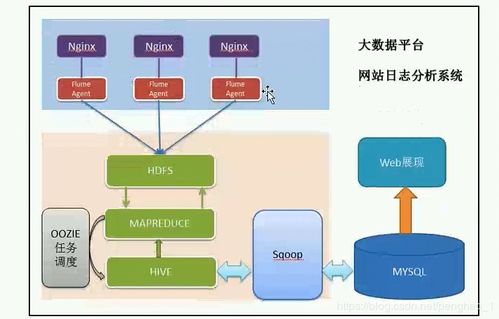
數據分片處理技術的核心在于將大規(guī)模數據集分割成多個較小的、易于管理的片段(即分片),并將這些分片分布到不同的處理節(jié)點或存儲設備上。每個分片可以獨立進行處理和存儲,從而實現(xiàn)了并行計算和負載均衡。這種分布式處理方式不僅提高了數據處理的速度,還通過冗余存儲增強了數據的可靠性和容錯能力。數據分片可以基于多種策略進行,如基于鍵值范圍的分片、基于哈希函數的分片或基于地理位置的分片等,以適應不同的應用需求。
在數據處理支持服務中,數據分片處理技術為實時數據分析和批量數據處理提供了強大的支持。例如,在實時數據分析場景中,數據流可以被動態(tài)分片并分配到多個處理節(jié)點,實現(xiàn)低延遲的數據處理和高吞吐量的數據攝入。在批量數據處理場景中,分片技術使得大規(guī)模數據集能夠被高效地并行處理,顯著縮短了數據處理周期。數據分片還支持彈性擴展,當數據量增長時,可以通過增加分片數量或節(jié)點來線性提升系統(tǒng)處理能力,而無需對現(xiàn)有架構進行大規(guī)模重構。
在數據存儲支持服務方面,數據分片處理技術通過分布式存儲架構解決了傳統(tǒng)集中式存儲的瓶頸問題。分片存儲不僅提高了數據訪問的速度,還通過數據冗余和備份機制確保了數據的高可用性和持久性。現(xiàn)代分布式數據庫系統(tǒng)(如MongoDB、Cassandra等)廣泛采用數據分片技術,以支持海量數據的存儲和快速查詢。分片存儲還便于實現(xiàn)數據的地理分布,滿足數據主權和合規(guī)性要求,為用戶提供全球化的數據存儲服務。
實施數據分片處理技術時,需綜合考慮多個關鍵因素。分片策略的選擇直接影響系統(tǒng)的性能和可維護性,需要根據數據特性和訪問模式進行優(yōu)化。分片間的數據一致性和事務處理是分布式系統(tǒng)中的經典挑戰(zhàn),需要采用適當的一致性協(xié)議(如兩階段提交、Paxos算法等)來保證。分片后的數據遷移和再平衡也是運維中的重要環(huán)節(jié),以確保系統(tǒng)在動態(tài)變化中的穩(wěn)定運行。
隨著人工智能、物聯(lián)網和邊緣計算的快速發(fā)展,數據分片處理技術將在更多領域發(fā)揮關鍵作用。例如,在邊緣計算場景中,數據可以在邊緣節(jié)點進行分片處理,減少中心云的壓力并降低延遲;在人工智能訓練中,分片技術可以加速大規(guī)模數據集的預處理和模型訓練過程。結合區(qū)塊鏈等新興技術,數據分片還能為數據安全和隱私保護提供新的解決方案。
數據分片處理技術作為數據處理和存儲支持服務的核心組件,通過分布式并行處理架構,有效應對了大數據時代的挑戰(zhàn)。它不僅提升了系統(tǒng)的性能和可擴展性,還為實時分析、批量處理和高可用存儲提供了堅實基礎。隨著技術的不斷演進和應用場景的拓展,數據分片處理將繼續(xù)推動數據處理與存儲服務向更高效、更智能的方向發(fā)展。企業(yè)和組織應積極擁抱這一技術,構建適應未來需求的數據基礎設施,以在數據驅動的競爭中保持領先地位。